GENERATIVE AI
STiVで生成AIの効果を最大化
生成AIを導入した企業の実態
-

AIが「専門知識」や「社内情報」に疎く、正しい回答を得られない
-

AIの回答に「もっともらしい嘘」が混じってしまう
-

AIに学習をさせたいが、時間とコストがかかりすぎる
STiVのアプローチ
RAG※で従来型GPTの課題を一掃
貴社の業務に直結する専門文献DBから回答を生成することで「嘘」を防止
-
従来型のGPT活用
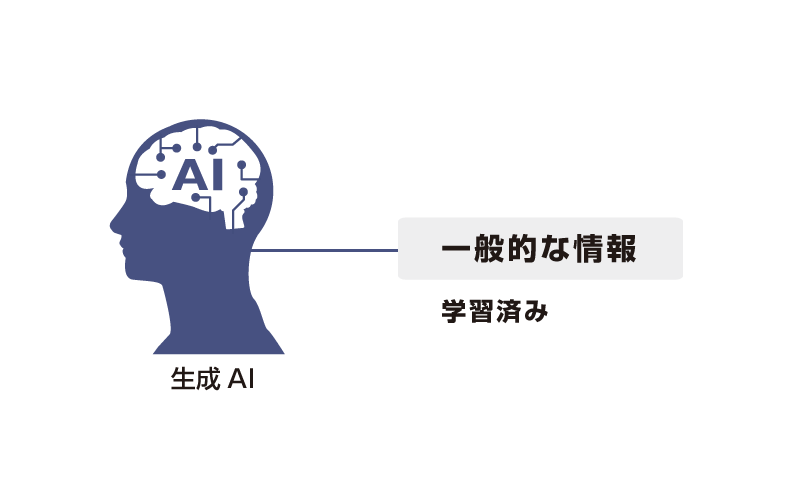
専門知識や社内情報に疎く
「嘘」を回答してしまうことも一般的な学習データを使用するため、専門知識や社内用語などについて質問すると正しい回答を得られない。
また、知らない情報に対し、既知の情報を組み合わせて、架空の情報・嘘(hallucination)を回答してしまう。
-
STiV
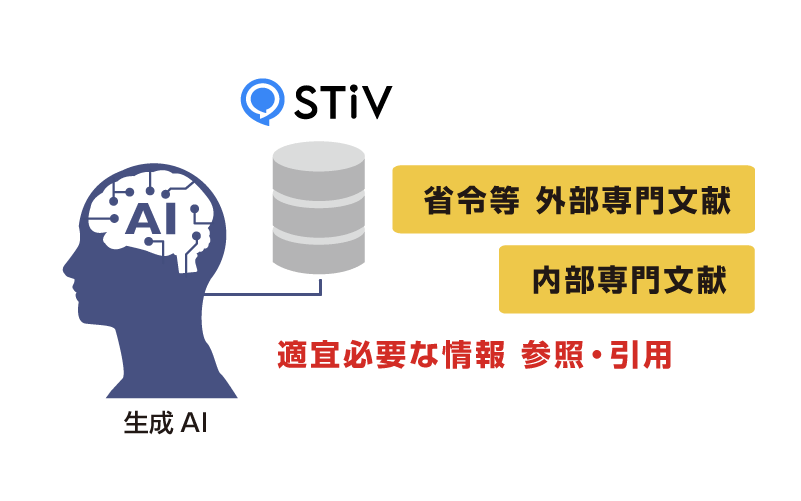
専門文献を元データに
精度が高く・正しい回答を生成専門文献や社内の過去資料などを検索したのち、検索結果を元にAIが精度の高い文章を生成。回答が一般化されず、専門的な質問や作業指示にも適切な回答を返却します。
また、検索にヒットしない情報には回答を生成しないことで、嘘の発生を防ぐことができます。
STiVのナレッジを活用し生成AI導入までの時間を大幅短縮
-
従来型のGPT活用
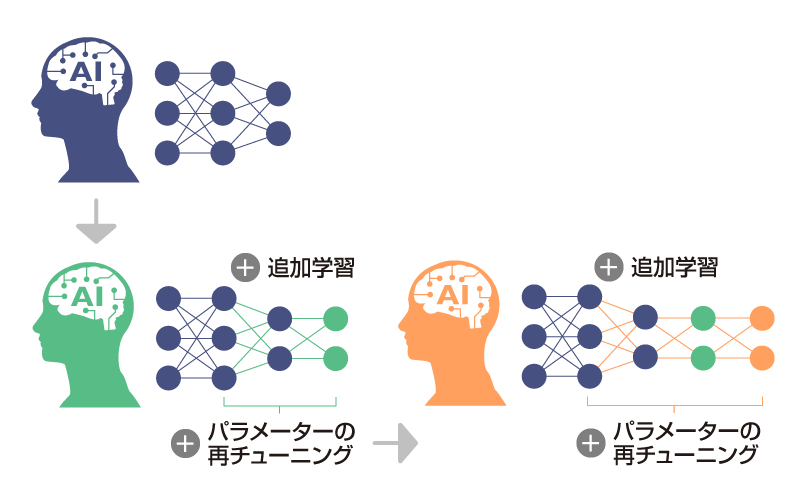
知識を追加するたびに
調整の時間とコストがかかる精度向上のためには、都度AIへの追加学習とチューニングが必要。チューニングは、学習済のパラメータにも施す必要があることから、最新データ利用には膨大な時間・コストを要する。
-
STiV
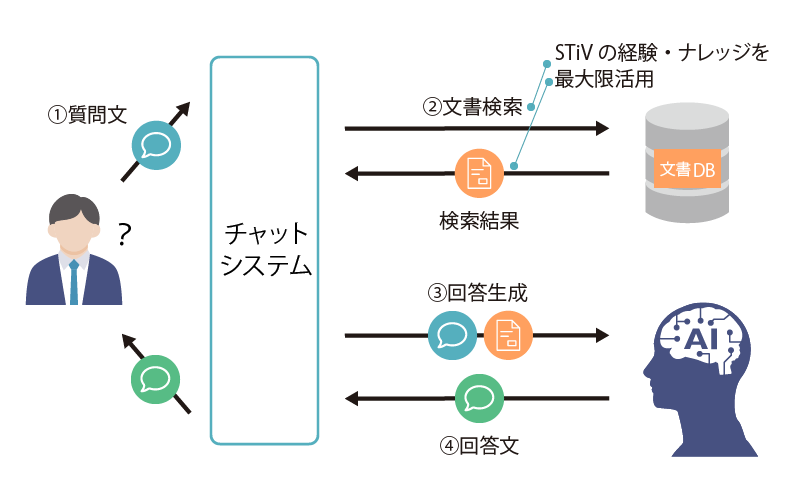
「AI+文書検索」の豊富なナレッジで
生成AIをすぐに活用「AIによる類似検索」や「AIによる検索結果の最適化」など、AI+文書検索はSTiVの本領。豊富な経験・ナレッジで、生成AIがより理解しやすく、回答精度を高められる検索結果を提供します。
時間のかかる生成AI側の調整を最低限に抑えることで、早期の生成AI導入を実現します。
※RAG
Retrieval Augmented Generation の略称で、米Meta社が2020年に発表した「検索拡張生成」のこと。
LLMの自然言語処理技術(NLP)に外部データベースのベクトル検索を組み合わせることで、LLMが生成する回答の精度、正確性を向上させようとするAIフレームワーク。